
Adina Wagner
September 19, 2020
What I learned from porting a MatLab toolbox
In short: The basics of good scientific programming and research software engineering. Plus, I got a one of my coolest papers out of it.
Introducing me, a noob
This post actually is about starting small, being stubborn, and about how small things like porting closed source software to open source software can not only help others, but also turn into something for your CV.
Back in 2017/18, I had a Bachelor’s degree in psychology, and worked towards my M.Sc. in Clinical psychology. I was broadly interested in basically everything, but I very happily describe my past self as a complete noob.
 🠔 That’s a good approximation of me in 20171.
🠔 That’s a good approximation of me in 20171.
For my Masters I picked a clinical psychology track2, but it contained one lecture series about functional neuroimaging. Michael Hanke, head of the Psychoinformatics Lab and co-creator of Neurodebian, PyMVPA, and DataLad, was the lecturer.
This lecture was the greatest lecture series of all my studies. It was fantastic. It was Physics, Linear Algebra, Statistics, and no need for memorizing, only really hard thinking and understanding, paired with Michael’s attitude of “I won’t force you to learn or understand, and I won’t be a bitch if you don’t care for this subject, but if you want to dive into this, I’ll give you everything you need to learn more.” I had never enjoyed university studies so much, and I deeply regretted not having picked the Cognitive Neuroscience Master track to which this lecture belonged.
So I asked Michael if I can write my thesis in the Psychoinformatics lab.
Did I mention I was a noob?
Before I started writing my thesis, I spent some months around the lab. I taught statistics as a tutor for Michael, and I hung out with the small team (a programmer, a system administrator, a Postdoc and a PhD student) trying to learn as much as I could. Because I had zero clue about anything my thesis would be about, I figured it would be beneficial to catch up.
Here’s an honest assessment of my programming experience up to that point in time:
- I had failed at self-teaching me Java during high school3.
- During my Bachelor’s degree, I took a LaTeX course for fun, and I gave another weekend course on Java programming a try4.
- During a research stay in the last year of my Bachelor I realized that I needed statistics in order to do science well, and so I attended a 3-day course in R for fun and continued with online courses on coursera.com and edx.org for the next few years.
- I had a computer that ran Windows 7, and displayed the curiosity of a toddler with a new toy towards it: I was incredibly interested in finding out how it worked, tried every possible thing with it, but also lacked the judgement of when I would accidentally break it5.
Beyond this, I’m also easily excited, stubborn enough to not stop if I want something, and easily influenced. All of that contributed to the decision to switch operating systems, and in February 2018 I asked my colleagues to help me install Debian on my computer.
Oh shit, I picked up Debian in a dungeon. 🠖 
What followed was the computer equivalent of being dropped in a remote Spanish village without speaking Spanish, but in a painful process, motivated by “I had left myself no other choice"™, I learned to use the command line up to a point where I could productively use my computer again.
Towards a thesis!
Michael had an interesting thesis topic for me that involved the joint analysis of eyetracking and fMRI data that was acquired while participants watched a movie from the studyforrest dataset. I didn’t have a clue about any of that. Nor how to write analysis scripts. BUT I was very confident: Michael had recommended me a book on Python programming, and I read it completely and knew abouts loops and objects and attributes, and none of that sounded too hard, and I had installed Python and copied the examples into the terminal, so I boldly proclaimed that I could now program in Python (hahahaha)6.

I brainstormed on how to use the eye tracking data for an analysis, and I found a MatLab toolbox for ScanPath comparison, the MutliMatch algorithm toolbox. I wrote the lead author of the publication, and he send me the toolbox right away.

Stubbornness can help
I had zero clue about MatLab, or MatLab toolboxes, or reading code that was not an example in a textbook, so I did what I was used to do with all kinds of other text I needed to understand: I printed it out and annotated it7. I then brought this stack of paper into a meeting with Michael and told him about the toolbox. He skimmed through it, to his huge credit did not laugh out loud8, and suggested porting it into Python9.
“Its not hard”, he said. And it definitely wouldn’t have been hard for him. Yet I had essentially zero skills in neither programming language (although I did know the difference between a method and an attribute in Python). But I believed him. I’m easily influenceable, after all.
Michael equipped me with a piece of advice for porting code that is a great as it is simple: Run the original once and note down the results. Once your code produces identical results, you’ve succeeded. And then I started to port the bloody toolbox into Python. And it took me ages. And I realized I didn’t know at all how to program in Python. And I spent hours at my desk, angry at the not-working code in front of me. But the thing that really made me finish it was when Michael told me, after a few weeks, that I shouldn’t actually port it, we could just analyze the data in MatLab, that would be easier for me10.
What I did wasn’t particularly exceptional: I turned about 30 printed pages of MatLab spaghetti code in Python spaghetti code. I looked at a line of MatLab code, I figured out what it was doing, and then I wrote a line of Python code that did the same. I very eagerly also ported all of the errors and the never-to-be-reached code into Python, but it would take me a few months to realize that.
Learning 1: The importance of version control
I started my porting by writing a Python script called MultiMatch.py.
I wrote all functions I ported in there.
But: A lot of the stuff I initially wrote was crap and malfunctional.
I would notice, delete the code, start over, realize that maybe the initial approach wasn’t to bad, be sad that I had deleted it, and so forth.
My initial solution to that was a series of nested directories that looked a bit like this:
MultiMatch
└── code
├── fail
└── final
├── final_new
│ └── FINAL
└── works
It was a mess.
Throughout the process of porting, I had dozens of files with almost identical names that contained slightly changed functions or produced different outputs of which I didn’t yet know what the correct one would be.
If the toolbox had been more complex, this endeavour would have been doomed to fail.
In the middle of all of this, I started to version control everything with Git.
It was still half-hearted, I still sticked to my established directory system, but I versioned it… somewhat. I kept forgetting to commit, or kept some files out of version control that I should have versioned, or had a neatly version control <file_v2.py> after I regarded <file.py> to be crap, but hey, we all start small.
But, in the end, after weeks, my code/final/FINAL directory had a single very long script, and it produced the same outputs than the MatLab toolbox.
I was so happy. 
Learning 2: Unit testing and test coverage
I told Michael about my success during lunch. He was happy, and recommended me to write tests for it 11. Then I read about unit tests, and wrote them. Soon I had some test, and I told Michael during lunch. Hey was happy, and recommended to aim for 80% coverage. I read about test coverage, and checked my initial tests coverage, and then wrote many many more unit tests. It was at this point that I realized that some code wasn’t reachable and other code was completely misbehaving - this was ported “verbatim” from MatLab, but I simply hadn’t noticed.
Learning 3: Open Code
Until now, I had ported the toolbox somewhat casually, in parallel to my normal semester and teaching. But the semester ended, and I left the lab to continue to write my thesis in the US, with Yarik, the co-creator of Neurodebian, PyMVPA, and DataLad, and work towards my thesis turned into a full-time activity.
I arrived and was proud to have this working. Yarik asked me to share the code and advised to put it on GitHub. And I did - and suddenly, I had an Open Source software.
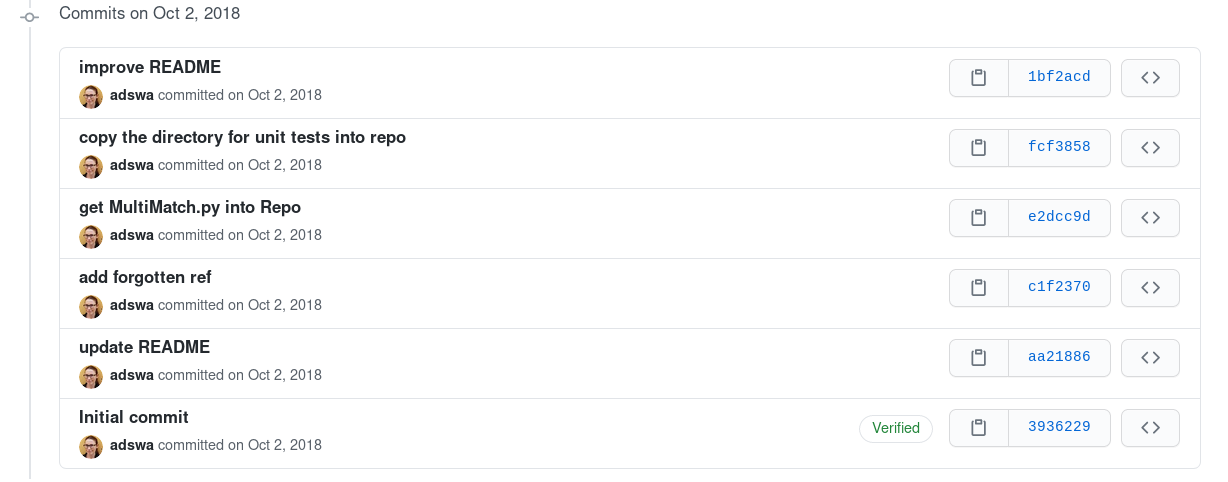
He told be about Continuous Integration. I read more about it, and set it up12.
Learning 4: Python packaging
So now I had a set of scripts on GitHub, unit tests, and continuous integration. I had a README badge with >80% code coverage.
 Yay!
Yay!
And, continuing the tradition of senior people casually telling me about things I had no idea I could do, Yarik asked my why I haven’t packaged it up.
Up to this point, I didn’t know “normal” people could package Python software.
Absolutely no idea.
But I googled how to do it, and, just as before, found a tutorial that showed me, and I did it.
It, again, took nights of swearing, and I’m very confident that my secret superpower is to do things wrong in all ways possible the first time I try them[#13], but eventually I had a package.
Took three minor versions until it was importable without throwing an error, but who cares - v.0.0.4 worked and everyone in the world could install it!
Learning 5: The importance of documentation
But if I wanted anyone to be able to use my software, I needed to have documentation for it. I had wished for documentation of the MatLab toolbox, too. Yarik told be about readthedocs, and, after some swearword-filled commits, I had set it up, and wrote my first ever software documentation. It was a lot of fun. But importantly, it was also the right time to do it. Because only a few months after that, I had to turn to the documentation myself to find out how to use it. I was a very happy user of my own documentation.
and then someone I didn’t know came around and improved it!
I vividly remember the joy I felt when one person “starred” the repo. And the excitement when someone I didn’t know created an issue. People were using this. What the fuck. But then someone came and created a pull request! And my continuous integration kicked in and tested their code! I spent about two weeks to long paralyzed about this. It was fantastic. As was their fix - it sped up my implementation of the algorithm hugely.
Did I mention I got a paper out of it?
I defended my thesis in February 2019. The toolbox was only a teeny-tiny aspect of it, but man, I was happy to have a slide about it in my defense. I was fucking proud that I turned closed source software into readily installable, tested, and documented open source software. And I had accidentally learned not only the basics of programming and understanding two programming languages, but also the basics of version control, unit testing, continuous integration, software documentation, collaboration on GitHub, and Python packaging.
I got my degree in Clinical Psychology. I think my second supervisor (a psychotherapist) is still confused about this.
And after the stress of thesis writing was over and I continued my journey with a PhD in the Psychoinformatics lab, I wrote up a 2-page summary of the tool, added it to GitHub, and submitted the repository to the Journal of Open Source Software. I invited Michael and Yarik to be my co-authors. This wasn’t without Michael reading through the code base once, and calling me out for having Python code that looked like MatLab code13. This was fun and embarrassing, but seeing someone else comment on and improve my code taught me lots of programming as well.
The review process at JOSS was a pleasure. And, without much more work, I had turned this project into a publication, the first during my PhD. The original author of the algorithm wrote me an email with thanks for making the algorithm accessible to more people after finding out via Google Scholar. People keep downloading the package more frequently that I ever imagined. Occasionally, there is another star or issue in the repo. Very rarely I meet someone in person who used the package. But all of that is so fucking cool, it was well worth all of the frustration. The key to everything were knowledgeable, patient and kind people that told me about concepts and best practices I had no way of knowing about. And other amazing people that wrote the tutorials and blog posts and HowTos and documentation that helped me implement it. Nothing I ever did as a psychologist felt that cool for me. Yay to open source software!
And also: Death to MatLab!
The character comes from the card game Munchkin. Its a fantastically fun game, in which you start as a human in a dungeon, and try to level up by acquiring as many absurd weapons and armour as possible, slaying monsters, and backstabbing your friends in fights. The card above depicts the dungeon curse “Duck of Doom”. If you draw it, the card says “You should know better than to pick up a duck in a dungeon. Lose 2 levels”. And some unarmed naive Munchkin that picks up random ducks in a Dungeon was about my mindset before I started this adventure. ↩︎
I’m not sure why, in general, I disliked talking to people ever since I started studying Psychology. ↩︎
I was interested in learning programming, but my school’s computer science classes consisted of learning to type with the ten-finger system. I got myself a introductory book on Java with a CD with exercises, but ended up frustrated and clueless after the crabs that should be “programmed to move around the display” kept running out of the display to never return (presumably because I didn’t add borders, but I’ll never now, because, unfortunately, the book didn’t have solutions to its exercises). With my crabs running away from me, I gave up. ↩︎
This one was much better, but it still didn’t really stick and I found comfort in not succeeding to program an alarm clock by questioning the philosophy behind that task. ↩︎
I broke it multiple times due to my fearlessness in installing whatever I found exciting. ↩︎
AHAHAHAHAHA. Haha. ha. I did, in fact, not know how to program in Python after reading a book on it. ↩︎
Whenever faced with MatLab code I actually still do that. Habits… ↩︎
Which is what everyone else in the lab did. But it had positive sides: Only this way, my lab mates noticed I used the text editor nano (about which they also laughed) and could point me to more powerful text editors such as vi. ↩︎
Our lab has a somewhat anarchist touch, and we’re heavy proponents of open source software. If you say MatLab too loud in our offices it could trigger anything between a stream of vomit to a public lynching. ↩︎
My thoughts in this moment were about the lines of “THE FUCK NO YOU FUCKER YOU TOLD ME THIS WAS FUCKING EASY AND I SPENT SO MUCH TIME AND ANGER ON THIS BLOODY SHIT SHOW THAT YOU SAID WAS EASY”. My outside reaction was trying to not let my thoughts get out of me. A few days later I then calmly told him that I would be too frustrated about all the worked I had poured into this already if I would give up now. I’m really stubborn, after all. ↩︎
For a solid week after that I still kept running around thinking a “test” would be one of the frequent
print()statements I had in my code. ↩︎Not that any of what I describe with “and I did it” was easy. Looking back at my commit history about trying to set up continuous is hilarious. And so wholesome. And so many swearwords. See for yourself. ↩︎
I didn’t say I wrote good code. It turns out, without knowing the “Pythonic” way of coding, porting MatLab to Python looks like Python with a strong MatLab accent or vice-versa. But it worked! ↩︎
comments powered by Disqus